Attention is all you need
- 글 화학생물공학부 2 하준석
- 편집 전기·정보공학부 3 이재형
서문
독자 여러분도 Chat GPT와 같은 대화형 인공지능 서비스를 자주 사용하시나요? 최근에는 사소한 것까지 물어볼 정도로 인공지능 서비스를 이용하는 사람이 굉장히 많아졌는데요, 마치 진짜 사람과 대화하는 느낌이 들 정도로 놀라움을 주기도 합니다. 이렇듯 대화형 인공지능 서비스는 뛰어난 성능을 바탕으로 사람들의 일상생활 속에 자리 잡았습니다. 그런데 이처럼 똑똑한 AI는 어떻게 사람처럼 생각하고 이야기하는 것일까요? 우리가 사용하는 한국어, 영어와 같은 언어를 컴퓨터 분야에서는 '자연어'라고 하는데요, 컴퓨터는 자신만의 독자적인 방법으로 인간의 언어인 자연어를 이해하고 소통합니다. 오늘은 컴퓨터가 어떻게 자연어를 처리하는지, 그 비밀을 파헤쳐보겠습니다.
본문
'오늘 책을 1권 읽었다'라는 문장의 의미를 단번에 쉽게 파악할 수 있는 인간과 달리 컴퓨터는 문장의 의미를 단번에 알아차리기 어렵습니다. 그래서 컴퓨터는 입력된 문장을 이해하기 위해 토큰(token) 개념을 사용합니다. 토큰이란 텍스트를 일정한 단위로 쪼갠 것을 의미합니다. 예를 들어, '오늘 책을 1권 읽었다.'라는 문장을 '오늘', '책', '을', '1', '권', '읽었다'로 쪼개어볼 수 있습니다. 그 다음으로 컴퓨터는 토큰들의 관계를 파악합니다. 예를 들어 '책'이라는 토큰은 '읽었다'라는 토큰과 연관이 깊다는 사실을 기억하고, 나중에 문장을 생성할 때도 이 사실을 활용하는 것입니다. 지금까지 이야기한 것처럼 컴퓨터는 입력된 문장을 토큰 단위로 쪼개어 이해하고, 생성할 때도 토큰 단위로 하나씩 생성합니다. 그렇기 때문에 자연어 처리 모델에서 가장 중요한 부분은 토큰 간 관계를 파악하는 방법입니다. 이 부분에 인공지능의 핵심이 숨어있습니다.
자연어 처리 모델은 기본적으로 인코더-디코더(Encoder-Decoder) 구조로 이루어져 있습니다. 인코더(Encoder)는 암호화 부분으로, 인간의 언어로 된 문장들을 받아 숨겨진 의미들을 파악합니다. 디코더(Decoder)는 디코더 모델을 이용하여 원하는 자연어 대답을 뽑아냅니다. 인코더와 디코더를 어떠한 방식으로 구성하는지에 따라 모델의 성능은 천차만별로 바뀌게 됩니다.
가장 처음으로 제시된 방식은 순환신경망(Recurrent Neural Net, RNN)입니다. RNN의 특징은 은닉층(Hidden State)과 토큰을 조합하여 다음 토큰을 순차적으로 생성한다는 점입니다. 먼저 인코더는 입력된 텍스트를 토큰으로 바꾸어 Hidden State를 생성합니다. Hidden State는 입력된 정보를 컴퓨터가 알아보기 쉽게 요약한 압축 데이터로, 디코더를 통해 출력할 때 사용하는 데이터입니다. 쉽게 말하자면, 입력된 데이터의 '기억'을 Hidden State로 저장하는 것입니다. 예를 들어 모델에 입력한 문장 X를 토큰 x0, x1, x2로 나누었다고 생각해봅시다. 컴퓨터는 가장 먼저 입력된 토큰인 x0를 통해 첫번째 Hidden State인 h0을 생성합니다. 이후 다음 토큰인 x1이 입력되고, 해당 정보가 h0에 반영되어 새로운 Hidden State인 h1을 생성합니다. 이때 h1은 컴퓨터의 '기억'이 갱신된 것이기에 x1뿐만 아니라 x0에 대한 정보도 담고 있습니다. 이런 과정이 한 번 더 반복되면 컴퓨터는 최종 Hidden State인 h2를 생성하게 됩니다. h2는 입력된 데이터를 압축적으로 기억하며, 디코더는 이를 이용해 적절한 출력을 생성할 수 있습니다. 요약하자면 RNN 방식은입력 토큰 x를 인코더에서 Hidden state h로 바꾸고, h를 바탕으로 출력 y를 만들어내는 방식입니다.
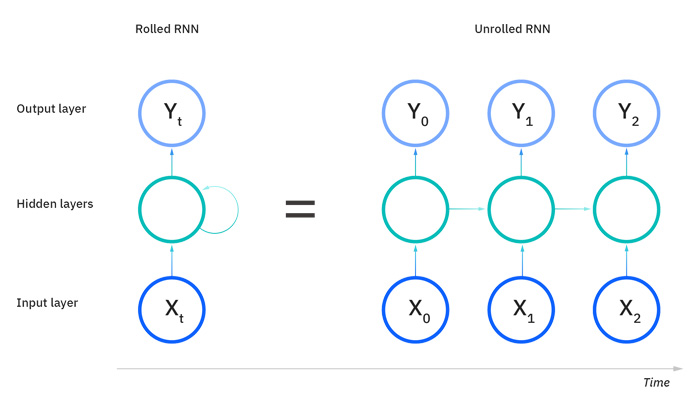
RNN 방식은 자연어 처리에 많은 강점을 가지지만, 몇 가지 문제점 또한 존재합니다. 첫 번째로, RNN 연산은 빅데이터 연산에서 중요한 '병렬 처리'가 어렵습니다. RNN은 토큰마다 hidden state를 갱신하는데, 이때 이전 상태의 Hidden State가 필요합니다. 따라서 병렬 데이터 처리가 불가능하며 순차적으로 연산해야 합니다. 결국 문장이 길어지면 매우 오랜 시간이 걸리게 됩니다. 예를 들어 100개의 토큰으로 이루어진 문장을 학습하기 위해서는 h1, h2, h3, … h100을 순차적으로 구해야 하기에 100개의 토큰을 한번에 학습할 수 없습니다. 두 번째로 RNN은 hidden state를 통해 과거 기억을 저장하지만, 모든 데이터를 저장할 수 있는 것은 아닙니다. 여러 토큰을 입력받으며 hidden state를 업데이트하다 보면 아주 오래전에 입력된 토큰에 대한 정보는 흐려질 수밖에 없습니다. 따라서 긴 글을 읽게 될 경우 초반부의 내용이 희미해지며 문맥 파악 능력이 자연스럽게 떨어지게 되는데, 이를 '기억 손실 문제'라고 합니다. 이러한 한계점을 극복하기 위해 오래되었더라도 중요한 정보는 저장해둘 수 있는 LSTM 방식이 등장하였지만, 여전히 병렬 처리가 불가능하다는 단점을 가지고 있었습니다.
인간과 대화할 수 있는 수준의 인공지능을 만들기 위해서는 방대한 양의 인간이 쓴 글을 읽고 학습하는 과정이 필수적입니다. 병렬 정보 처리 없이는 충분한 학습이 이루어지기 어렵기에, 기존 방식으로 인간과 비슷한 수준의 대화가 가능한 인공지능을 구현하는 것은 불가능에 가까웠습니다. 그러나 2017년, 인공지능의 패러다임을 완전히 바꾸어 놓은 모델이 등장합니다. 바로 논문 'Attention Is All You Need'를 통해 발표된 트랜스포머(Transformer)입니다.
Transformer 모델은 어텐션 메커니즘(Attention Mechanism)을 통해 데이터를 처리하는 방식을 새롭게 제안합니다. Attention 방식은 모든 텍스트를 같은 중요도로 처리하지 않고, 주요 단어들에 집중합니다. 마치 공부할 때 모든 내용을 전부 다 보지 않고, 중요한 내용에 밑줄을 치는 것과 같습니다. 그렇다면 텍스트 내에서 어떤 단어가 중요한지 어떻게 파악할 수 있을까요?
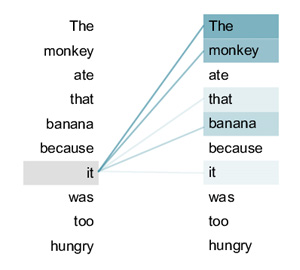
어텐션(Attention)은 주목도, 즉 두 단어가 서로 얼마나 연관되었는지를 수치적으로 나타냅니다. 어텐션 메커니즘은 Attention을 계산하기 위해서 Q(Query), K(Key), V(Value) 3개의 값을 이용합니다. Query는 현재 처리 중인 단어가 찾고자 하는 정보, Key는 입력 시퀀스의 각 단어가 가지고 있는 특성 또는 설명, Value는 실제로 전달할 정보 그 자체를 의미합니다. 이렇게 보면 의미가 잘 와닿지 않으니 실제 예시를 통해 Q, K, V를 이해해 봅시다. 'He didn't bought the book because it was so expensive'라는 문장이 입력되었을 때, 컴퓨터는 'it'이 무엇을 가리키는지를 알아내야 합니다. 이때의 Q는 'it', K는 주변의 토큰들인 'He', 'didn't', 'bought', 'book' 등을 의미하며, 이 둘을 통하여 단어의 중요도 및 'it'과 가장 높은 유사도를 갖는 단어를 계산해냅니다. 위 문장의 예시에서 컴퓨터는 Q와 K값들의 연산을 통하여 'it'이 'book'을 의미함을 파악할 수 있으며, 문장 내에서 해당 단어가 얼마나 중요한지를 알아낼 수 있습니다. V는 각 토큰에 대한 문맥 정보로 해당 상황에서는 'it'에 대한 V는 'book'이라고 생각해볼 수 있습니다. 즉, Attention은 Q와 K를 통해 해당 토큰이 주변 토큰과 어떤 연관성을 갖는지 계산하여 이를 바탕으로 중요도를 평가하고, 토큰의 정보를 Value에서 꺼내오는 과정입니다. 이렇게 입력된 토큰들에 대한 Attention을 계산하여 문장 속에서 다른 단어들과의 문맥적 관계, 중요도를 파악할 수 있습니다.
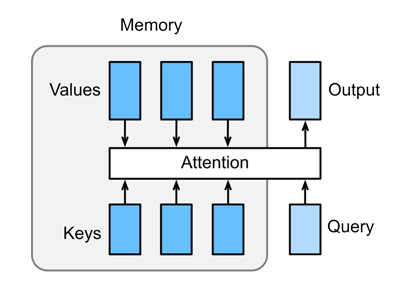
Attention 방식을 통해 자연어 처리 모델은 기존 방식이 가지던 한계점을 극복하였습니다. 앞서 살펴본 것처럼 기존 방식은 토큰 간 거리가 멀어지면 정보 전달이 힘들었고, 병렬 정보 처리가 불가능하였습니다. 그러나 Attention 방식은 모든 토큰 간의 상호 관계를 계산하는 연산이 전부, 동시에 이루어집니다. 따라서 토큰 간의 거리와 무관하게 연관성을 파악할 수 있으며, 병렬 처리 또한 가능합니다.
하지만 Attention 방식에도 약점이 있는데요, 바로 연산량이 너무 많다는 점입니다. 직전에 생성한 토큰과 hidden state만을 이용해 다음 토큰을 생성하는 RNN 방식과 달리 Attention 방식은 각 토큰이 나머지 모든 토큰과 각각 얼마나 관계가 있는지 전부 계산합니다. 그렇기 때문에 연산량이 너무나 많아질 수밖에 없습니다. 이에 대한 부담을 줄이기 위해 등장한 방식이 KV 캐시(KV Cache)입니다. 'Cache'는 컴퓨터 과학에서 자주 등장하는 용어인데요, 다시 사용할 것 같은 연산 결과를 따로 저장해 중복 연산을 피하는 방식입니다. KV Cache는 Attention 연산 중 얻어낸 K와 V의 값을 기억한 뒤, 다음 토큰이 들어왔을 때 재연산 없이 곧바로 그 값을 이용합니다. 새로운 토큰이 들어왔을 때 처음부터 모든 연산을 하지 않고 직전의 연산 결과를 가져오면 되기 때문에, KV Cache를 이용하면 데이터 학습 속도와 효율이 더욱 향상됩니다.
Attention 메커니즘을 바탕으로 한 인공지능 모델인 Transformer는 현재 딥러닝의 표준 모델로 사용되고 있습니다. RNN과 마찬가지로 Transformer 역시 인코더-디코더 구조로 이루어져 있습니다. 인코더는 입력 시퀀스의 의미를 파악하기 위하여 입력받는 시퀀스의 토큰들 간 Attention을 연산합니다. 이를 'Self-Attention'이라고 합니다. 'self'란 시퀀스 자기자신 내부에서 관계를 파악하는 것을 의미합니다.
한편 디코더에서는 실시간으로 출력이 생성됩니다. 어떤 중간 상태에서 다음 토큰을 생성하기 위해서는 두 가지 Attention을 이용합니다. 첫 번째는 인코더처럼 출력 중인 시퀀스 자기자신 내부의 관계성을 확인하는 Masked Self-Attention입니다. 예를 들어 출력이 '나는 공과대학 소속의'까지 생성되었다면, '나는', '공과대학', '소속의' 토큰들 사이 Attention을 하여 자연스러운 다음 토큰이 무엇인지 예측하는 방식입니다. 용어에서 알 수 있듯이, 인코더의 Self-Attention과 다른 점은 '마스킹(Masking)'이 필요하다는 점입니다. 'Masking'이란 특정 토큰을 가려두는 것을 의미합니다. 인코더는 완성된 문장을 입력받지만 디코더는 실시간으로 문장을 생성 중이기 때문에 미래의 정보는 이용하지 않고자 가려두고 연산을 진행합니다. 예를 들어 인코더는 '나는 공과대학 소속의 학생입니다'에서 모든 토큰 간 Attention을 하지만, 인코더는 '소속의'를 생성할 때 '학생입니다' 토큰과 Attention을 이용해서는 안 됩니다. 두 번째는 Cross-Attention으로, 출력 중인 시퀀스와 인코더에서 입력받은 시퀀스의 관계를 파악합니다. 예를 들어, '나는 학생이다.'라는 문장을 실시간으로 영어로 번역하는 상황이라면, 'I am a' 다음으로 올 토큰을 생성할 때 입력 토큰 중 '학생'과의 Attention에 높은 점수를 부여합니다. 이에 영향을 받아 다음 출력 토큰으로 'student'가 나올 가능성이 높아집니다.' 이렇게 두 가지 Attention을 이용하여 디코더는 정확성 높은 출력을 생성할 수 있습니다.
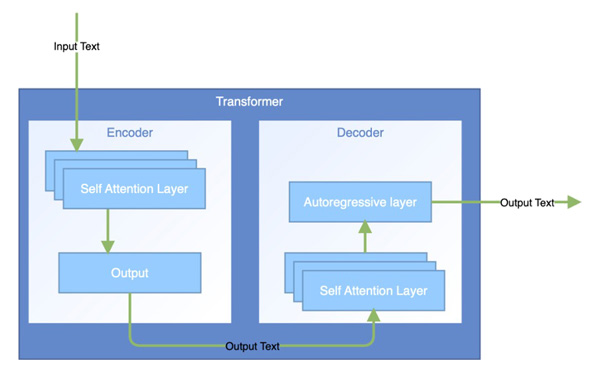
Transformer의 등장으로 인공지능 분야는 크게 성장할 수 있었으며, 그 결과 Chat GPT와 같은 AI들이 개발되는 데 결정적인 영향을 주었습니다. Transformer의 구조가 실시간으로 텍스트를 받아들이고 생성하며 문맥을 파악하기에 매우 용이한 구조이기 때문입니다. 이전의 대화 내용과의 관계를 파악할 수 있기에 AI가 단순한 질의응답을 넘어 상대와 대화를 하는 것이 가능해졌으며, 효율적인 텍스트 처리로 큰 용량의 파일도 빨리 읽을 수 있게 되었습니다. 기존 방식의 단점을 완벽히 보완하는 좋은 성능을 보이며 Transformer는 단시간에 AI 학습의 표준 모델로 자리 잡았습니다. 더 나아가 현재는 이미지 분석, 음성 인식 등 대부분의 AI 활용 분야에서 기반 모델로 활용되고 있습니다.
최근 인기를 끌고 있는 'Chat GPT로 그림 그리기'에도 Transformer가 이용됩니다. 이미지 출력은 단순한 텍스트 입출력보다 훨씬 많은 연산을 요구합니다. 또한, 이미지는 텍스트에 비해 훨씬 자연스러운 결과 생성이 필요하기에 주변 데이터와의 관계가 더욱 중요합니다. AI를 통한 문장 생성은 토큰들에 대한 계산이었다면, 이미지 생성성은 픽셀들에 대한 계산입니다. 텍스트에서 “다음에 올 토큰이 무엇일까”에 대한 문제가 “다음에 올 픽셀이 어떤 색상일까”로 확장된 것입니다. Transformer을 기반으로 하여 text to image 모델이 이전보다 높은 수준으로 제시, 점점 발전해 나가며 현재는 매우 자연스러운 수준까지 도달하게 되었습니다.

이전 호에서 다루었던 'Alphafold' 역시 Transformer를 기반으로 개발되었습니다. 'Alphafold'는 아미노산 서열에 따른 단백질 구조를 예측하는 프로그램이기에 수천에서 수만 개의 아미노산 서열 정보를 빠르게 처리할 수 있어야 합니다. 이 상황은 자연어 문장의 토큰 간 관계를 계산한 것과 매우 유사하기에 Transformer를 사용하여 신속한 구조 예측 계산이 가능해집니다. 특히, 어느 지점에서 어느 각도로 구조가 접힐지 예측하기 위해서는 각 아미노산이 다른 아미노산과 어떤 상호작용을 갖는지를 모두 계산하는 과정이 필요합니다. 이때 self-attention을 이용하면, 주변의 아미노산과의 관계를 파악하기 매우 쉬워지게 됩니다.
Attention 방식은 등장한 지 아직 10년도 안 되었지만, AI의 역사에 지대한 영향을 주었으며 다양한 분야에서 활용되고 있습니다. Attention 방식을 기반으로 한 다양한 인공지능 모델들은 여전히 계속해서 발전 중이며 AI는 계속해서 학습을 진행하고 있습니다. 앞으로 더욱 발전할 AI의 시대, 나아가 이를 활용하여 발전할 다른 분야의 기술까지 기대해봅시다!
참고문헌
- 1. Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. "Attention Is All You Need." In Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS 2017), Long Beach, CA, USA. arXiv:1706.03762
- https://www.ibm.com/kr-ko/think/topics/recurrent-neural-networks
- https://www.ibm.com/kr-ko/think/topics/transformer-model
그림 출처
- 그림1. https://www.ibm.com/kr-ko/think/topics/recurrent-neural-networks
- 그림2. https://www.researchgate.net/figure/An-example-of-the-self-attention-mechanism-following-long-distance-dependency-in-the_fig1_350714675
- 그림3. Zhang, Aston and Lipton, Zachary C. and Li, Mu and Smola, Alexander J. from https://github.com/d2l-ai/d2l-en with UploadWizard
- 그림4. https://vectorize.io/blog/what-is-a-transformer-in-gen-ai
- 그림5. 넷플릭스 홈페이지, Chat GPT