HBM - AI의 심장을 만드는 K-반도체
- 글 화학생물공학부 1 박건영
- 편집 건설환경공학부 4 조한기
서론
요즘 Chat GPT나 Gemini 같은 생성형 인공지능을 많이들 사용하고 계실 겁니다. 이런 AI가 점점 정교해지면서 동시에 다뤄야 하는 변수, 즉 파라미터의 수가 폭발적으로 늘어나고 있는데요. 예를 들어 Chat GPT는 약 5천억 개의 파라미터를 거의 동시에 처리한다고 합니다. 이렇게 방대한 양의 데이터를 어떻게 저장하고 빠르게 처리할 수 있을까요?
불과 10년 전만 해도 이러한 인공지능 개발에서 메모리는 큰 걸림돌이었습니다. 처리를 위해 한 번에 많은 데이터를 주고받는 것이 어려웠기 때문입니다. 이 문제를 해결한 것이 바로 HBM이라는 새로운 형태의 메모리입니다. 단순한 저장 장치를 넘어, 오늘날의 고성능 AI가 작동할 수 있게 만든 핵심 기술이 된 것이죠.
그렇다면 HBM은 어떤 기술이고, 왜 이 작고 정교한 메모리를 두고 다양한 반도체 기업 간 경쟁이 벌어지고 있는 걸까요? 지금부터 그 이야기를 함께 살펴보겠습니다.
1. HBM1)의 탄생: 평면의 한계를 넘어서 3차원으로
HBM의 등장 이전, GPU2)의 빠른 연산을 위해서는 GDDR3) 메모리가 사용되었습니다. GDDR 역시 일반적으로 사용되는 DRAM과 달리, 더 많은 정보를 동시에 전송할 수 있도록 병렬적으로 설계되어 있었고, 그 덕분에 약 10배에 달하는 대역폭을 제공하며 컴퓨터 게임과 같이 고성능 연산이 요구되는 분야에 널리 활용되었습니다. 하지만 이러한 GDDR에도 한계는 존재했습니다. 메모리와 연산 장치인 GPU의 물리적 거리를 최소화하기 위해 GDDR을 GPU 주변에 둘러 배치했지만, 칩을 평면적으로 배열하는 구조상 일정 이상의 수를 배치하기 어려웠고 이는 대역폭 증가의 어려움으로 이어졌습니다.
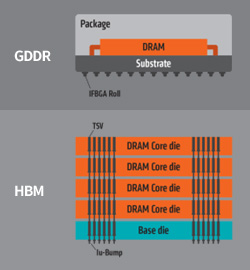
이런 상황에서 2013년, SK 하이닉스와 AMD에 의해 1세대 HBM이 개발되었습니다. 평면적 배열의 한계를 극복하기 위해 DRAM을 수직으로 전기적 연결하자는 아이디어를 실행에 옮겼습니다. 그 결과 물리적으로 더 많은 DRAM 소자들을 GPU 근처로 이동시킬 수 있었고 GDDR이 가지고 있던 문제를 해결했습니다.
한편, 초기의 HBM은 기존 GDDR에 비해 가격이 매우 비쌌고, 열 밀도가 높아 냉각이 까다로우며, 복잡한 공정 구조로 생산 수율도 낮았기 때문에 시장의 주목을 받지 못했습니다. 하지만 이러한 문제점들은 HBM2, HBM3, HBM3E로 세대가 바뀌며 공정 최적화와 설계 개선을 통해 점차 해결되었고, 오늘날 HBM은 AI 시대의 방대한 연산과 데이터 흐름을 감당하는 데 없어서는 안 될 핵심 메모리 기술로 자리 잡았습니다.
이러한 기술적 진보는 HBM 시장의 급성장으로 이어졌고, 현재는 글로벌 반도체 기업들이 앞다퉈 고대역폭 메모리 경쟁에 뛰어들고 있습니다. 그렇다면 현재 HBM 기술의 주도권은 누가 쥐고 있을까요?
2. HBM 3강 시대의 본격화: TSV로 앞서는 SK하이닉스, 추격하는 경쟁사들
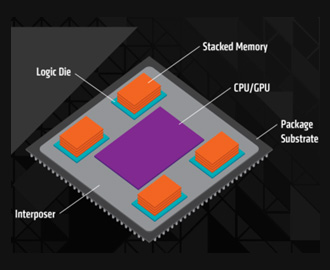
앞서 언급했듯이, 초기 HBM은 발열, 수율4), 가격 등 여러 단점을 안고 있었고, 불과 10년 전만 해도 GDDR 메모리만으로도 대부분의 연산 요구를 충족할 수 있었기에 HBM은 한동안 시장 주류에서 벗어나 있었습니다. 실제로 2019년, 삼성전자는 HBM의 시장성을 낮게 평가하며 관련 부서를 축소·해체한 바 있습니다.
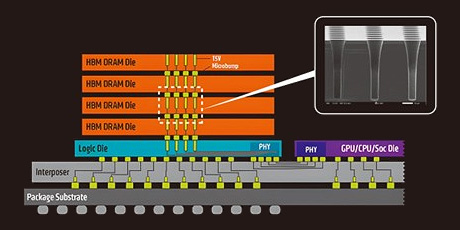
그러나 2023년, 초거대 AI 모델의 확산으로 연산 수요가 폭발적으로 늘어나면서 HBM에 대한 글로벌 수요가 급격히 증가했습니다. 이때, 꾸준한 기술 투자를 지속한 SK하이닉스는 TSV 공정에서 강점을 발휘했습니다. TSV는 얇은 메모리 칩을 여러 장 쌓아 미세 전극으로 위 아래까지 관통 연결하는 기술입니다. 마치 아파트를 층층이 쌓고 각 층을 연결하는 엘리베이터를 설치하는 것처럼, 수천 개의 데이터 통로를 동시에 열어 초고속 전송을 가능하게 합니다. 그러나 한 층이라도 문제가 생기면 전체가 불량이 되기 때문에 HBM 제작에 가장 어려운 과정으로 평가받습니다.

SK하이닉스는 층과 층을 붙이는 접착제의 소재를 개선해 이 문제를 극복했습니다. 온도가 증가할 때 팽창하는 정도를 정밀하게 설계한 접착제로 칩 사이의 틈을 메우고, 빠르게 굳히는 과정을 조절하여 층간 어긋남과 기포를 최소화했습니다. 이러한 기술 덕분에 SK하이닉스는 많은 층을 쌓는 HBM3E까지 안정적으로 대량생산할 수 있었고, 현재 이 시장에서 90% 이상 점유율을 차지하며 독보적인 입지를 이어가고 있습니다.
반면 삼성전자는 2024년 4월 엔비디아의 테스트에서 HBM3 인증에 실패하며 공급이 무산됐지만, 같은 해 6월 AMD의 AI 칩에 HBM3E 공급을 성사하며 반격에 나섰습니다. 미국의 마이크론도 초기 개발이 늦어 점유율 확보에 어려움을 겪었으나, 4월 엔비디아 테스트를 통과해 SK하이닉스가 독점하던 공급망에 합류했습니다. 이처럼 SK하이닉스의 독주는 삼성과 마이크론의 추격 속에 점차 다극 체제로 재편되고 있습니다.
3. HBM 기술: 성능 경쟁에서 수요 맞춤 경쟁으로
HBM 기술의 다음 세대로 주목받는 HBM4를 둘러싼 시장은 이전 세대와는 사뭇 다른 양상을 보이고 있습니다. 지금까지는 대역폭 향상, 수율 개선, DRAM 적재 용량 확대 등 공통의 기술 목표를 중심으로 경쟁이 이루어졌다면, HBM4부터는 다양한 고객사들의 요구에 맞춘 제품 개발이 주요 전략으로 자리 잡고 있습니다. AI 모델의 연산을 담당하는 AI 가속기는 제조사마다 요구 사양에 차이가 있습니다. 어떤 고객은 최대 대역폭을, 어떤 고객은 저전력 설계나 열 안정성을 우선시하기 때문에, 이에 맞춰 HBM 생산 시장도 맞춤형 방식으로 변화하고 있는 것입니다. 시장에서는 이러한 HBM4의 예상 상용화 시기를 올해 말로 예상하고 있는데, 일찍이 HBM4 개발을 시작한 삼성전자는 올해 7월 안으로 HBM4 샘플을 고객사에 공급하기로 밝히며 차세대 HBM 시장 주도권 확보를 위한 본격적인 작업에 나서고 있습니다.
결론
HBM이라는 작은 메모리 칩은 오늘날의 인공지능과 자율 주행 기술을 가능하게 만든 핵심 부품입니다. 눈에 잘 띄지는 않지만, 이 조그마한 소자를 누가 더 정교하게 만들고 먼저 상용화하는지를 두고 삼성전자와 SK하이닉스를 비롯한 글로벌 반도체 기업들이 치열한 기술 경쟁을 벌이고 있습니다. 최근에는 엔비디아뿐 아니라 AMD 등 다양한 기업에서도 HBM 수요가 급증하면서, 관련 시장은 올해 약 182억 달러에서 내년 467억 달러 규모로 성장할 것으로 전망되고 있습니다. 보이지 않는 데이터의 흐름을 책임지는 AI의 심장, 고대역폭 메모리인 HBM 기술의 패권을 과연 어느 기업이 거머쥐게 될지, 앞으로도 흥미 있게 지켜봐주세요!
참고 문헌
- 1. 문화일보. 「'챗GPT의 파라미터 수는?'」 문화일보, 2024. https://www.munhwa.com/article/11418966
- 2. 연합뉴스. 「'마이크론, 엔비디아에 HBM3E 공급 시작'」 연합뉴스, 12 Apr. 2025. https://www.yna.co.kr/view/AKR20250412026100003
- 3. 한국경제. 「'초고속 D램 HBM, 2032년 시장 100조원 육박'」 한국경제, 4 Nov. 2024. https://www.hankyung.com/amp/2024110478241
- 4. Reuters. "Samsung's HBM Chips Failing Nvidia Tests Due to Heat, Power Consumption Woes - Sources." Reuters, 23 May 2024. https://www.reuters.com/technology/samsungs-hbm-chips-failing-nvidia-tests-due-heat-power-consumption-woes-sources-2024-05-23
- 5. SK hynix Newsroom. "One Team Spirit: SK hynix's Journey to HBM Leadership." SK hynix, 2024. https://news.skhynix.com/one-team-spirit-sk-hynix-journey-to-hbm-leadership
참고
- 1) High Bandwidth Memory, 메모리 칩을 위로 쌓아 만든 구조의 메모리. 작고 빠르며 전력도 적게 써서 AI나 자율주행 등에 적합함.
- 2) Graphics Processing Unit, 그래픽 처리나 AI 연산처럼 많은 계산을 빠르게 처리하는 컴퓨터용 칩.
- 3) Graphics Double Data Rate, GPU에 쓰이는 고속 메모리. 일반 메모리보다 빠르고 동시에 많은 데이터를 처리할 수 있음.
- 4) 생산된 반도체 중 정상적으로 작동하는 제품의 비율. 수율이 낮으면 원가가 높아짐
그림 출처
- 그림1, 2. Anand Lal Shimpi. "AMD's HBM Deep Dive." AnandTech, 2015. https://www.anandtech.com/show/9266/amd-hbm-deep-dive/3
- 그림3. PC Perspective. "JEDEC Updates HBM Standard with 24GB Capacity and Faster Speed." PC Perspective, 12 Dec. 2018. https://pcper.com/2018/12/jedec-updates-hbm-standard-with-24gb-capacity-and-faster-speed/
- 그림4. 뉴스웨이. 「'HBM 전쟁, 다시 타오른다'」 뉴스웨이, 21 Apr. 2025. https://www.newsway.co.kr/news/view?ud=2025042113271374639