공대생은 걸음도
코딩해서 걷는다
- 글 컴퓨터공학부 2 임태빈
- 편집 건축학과 4 권나경
드넓은 캠퍼스, 효율적인 이동은 공대생의 숙명!
서울대학교 캠퍼스는 그 광활함으로 유명합니다. 200개가 넘는 건물 안에는 각종 단과대학 연구소는 물론 은행, 헬스장, 수영장, 미술관까지 자리하고 있습니다. 관악산 속 캠퍼스는 아름다운 풍경을 선사하지만, 동시에 캠퍼스 내 이동에 큰 어려움을 주기도 합니다. "정문에서 윗공대는 걸어서 가지 말라"는 이야기가 있을 정도지만, 공대생에게 불가능이란 없죠! 넓은 서울대학교 캠퍼스의 주요 건물들을 코딩으로 탐험해볼까요?
TSP, 그게 뭐에요?
효율적으로 탐험하는 방법을 고민하다 보면, 자연스레 외판원 문제(Traveling Salesperson Problem, TSP)에 흥미를 갖게 됩니다. 외판원 문제란, 여러 지역을 도는 판매원(외판원)이 모든 지역을 돌고 다시 출발점으로 돌아와야 한다고 할 때, 최적의 경로를 찾는 문제입니다. 이는 물류 최적화1), 배송 경로 설정 등 다양한 분야에서 중요한 문제로 다뤄지고 있습니다. 이번 시간에는 서울대학교의 건물들을 둘러보는 외판원이 되어 가장 효율적인 동선을 코딩해봅시다.
TSP 문제를 해결하기 위한 다양한 알고리즘이 존재하는데요. 이번 기사에서는 몇 가지 대표적인 알고리즘을 소개하고, 이를 서울대학교 캠퍼스 건물 간 최적 경로 탐색에 적용하여 그 성능을 비교해 볼 예정입니다. 우리가 살펴볼 알고리즘은 다음과 같습니다.
- 완전 탐색(Brute Force): 가능한 모든 경로를 탐색하여 최적의 경로를 찾는 가장 기본적인 방법입니다. 단, 예를 들어 도시의 수가 늘어날수록 계산량이 폭발적으로 증가하는 등 단점이 있습니다.
- 동적 계획법(Dynamic Programming): 문제를 작은 부분으로 나누어 해결하고, 그 결과를 저장하여 재활용하는 방식입니다. 완전 탐색보다는 효율적이지만, 여전히 문제 크기에 따라 계산량이 크게 늘어날 수 있습니다.
- Greedy MST 기반 근사 알고리즘: 최소 신장 트리(Minimum Spanning Tree, MST)2)를 활용하여 최적에 가까운 해를 비교적 빠르게 찾아내는 방법입니다. 정확성은 보장되지 않지만, 비교적 짧은 시간 내에 좋은 해를 구할 수 있다는 장점이 있습니다. 그렇기에 속도가 중요한 상황에서 쓰이기 적합합니다.
이제, 본격적으로 외판원이 되어 캠퍼스를 누벼볼까요? 물론 공대생답게 효율적으로 말이죠!
1단계. 가중치 그래프, 현실의 지도를 코드로 옮기기
효율적인 경로 탐색을 위해서는 캠퍼스 지도를 기반으로 그래프(Graph)를 구성해야 합니다. 컴퓨터 과학에서 그래프란 현실 세계의 복잡한 관계를 점에 해당하는 노드(Node)와 두 점을 잇는 간선(Edge)으로 단순화한 모델입니다. 이를 서울대학교에 적용하면, 각 건물이 바로 '노드'가 되고, 이 건물들 사이를 이동하는 데 소요되는 시간이 '간선'이 됩니다.
하지만 각 건물 사이의 소요 시간 즉, 간선은 거리에 따라 달라지게 됩니다. 이때 필요한 것이 바로 각 간선에 '가중치(Weight)'3) 또는 '비용(Cost)'이라는 숫자 값을 부여한 가중치 그래프(Weighted Graph)입니다. 우리의 '서울대학교 캠퍼스 탐방' 문제에서는 각 건물 사이를 도보로 이동하는 데 걸리는 '예상 소요 시간'이 바로 이 가중치가 됩니다.
// Python 코드
graph_simple = {
'A': {'B': 10, 'C': 15, 'D': 20, 'E': 25},
'B': {'A': 10, 'C': 35, 'D': 25, 'E': 30},
'C': {'A': 15, 'B': 35, 'D': 30, 'E': 20},
'D': {'A': 20, 'B': 25, 'C': 30, 'E': 10},
'E': {'A': 25, 'B': 30, 'C': 20, 'D': 10}
}
print(graph_simple)
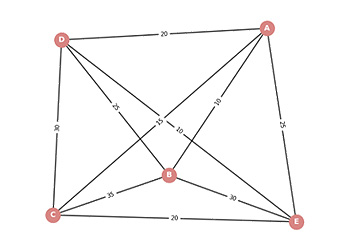
우선, 간단한 예시를 통해 그래프를 코드로 표현하는 방법을 알아보겠습니다. 위 그림은 5개의 노드로 이루어진 가중치 그래프입니다. 위 코드는 그래프를 '각 노드에 대해 연결된 노드' - '그 사이 간선의 가중치 값'을 쌍으로 순차적으로 저장한 딕셔너리4)를 정의한 것입니다.
위 코드에서 각 키5)('A', 'B', 'C', 'D', 'E')는 건물을 나타내며, 각 키에 대한 값은 다른 건물과의 연결 정보와 이동 시간(가중치)을 담고 있습니다. 예를 들어, 'A': {'B': 10, 'C': 15}는 A 건물에서 B 건물까지 이동하는 데 10분이 걸리고, C 건물까지 이동하는 데 15분이 걸린다는 의미입니다.
가중치 그래프의 기본적인 구조는 위와 같습니다. 실제 서울대학교 캠퍼스 전체에 대한 그래프는 더 많은 노드와 간선 정보를 포함하여 그래프를 시각적으로 이해하기 어렵기 때문에 기본 구조를 사용하여 알고리즘 성능 비교를 진행하고자 합니다.
2단계. 알고리즘 구현 및 성능 비교
자, 이제 본격적으로 코딩의 세계로 뛰어들어 볼까요? 앞에서 소개한 세 가지 알고리즘을 파이썬(Python)으로 직접 구현하고, 우리가 만든 서울대학교 캠퍼스 그래프에 적용해 보겠습니다. 과연 어떤 알고리즘이 가장 효율적인 경로를 찾아낼까요?
알고리즘 시연을 위해 앞에서 만들었던 5개 건물로 구성된 간단한 그래프(graph_simple)로 각 알고리즘에 대한 간단한 실습을 진행하도록 하겠습니다.
1. 완전 탐색(Brute-Force): 모든 경로를 파악한다!
가장 직관적인 방법입니다. 시작점을 제외한 모든 건물을 방문하는 순서의 모든 경우의 수를 확인하고, 그중 가장 짧은 경로를 선택합니다. 파이썬의 itertools 라이브러리를 사용하면 모든 순열을 쉽게 만들 수 있습니다. 만약 방문할 건물이 13개라면, 이 모든 순서를 직접 코드로 짜는 것은 매우 복잡하고 어렵습니다. 이때 순열을 자동으로 짜주는 역할이 바로 itertools입니다.
Python
import itertools
import sys
def tsp_brute_force(graph, start_node):
nodes = list(graph.keys())
nodes.remove(start_node)
min_path_cost = sys.maxsize
best_path = []
# 시작점을 제외한 모든 노드의 순열 생성합니다.
# itertools의 permutations 함수를 사용합니다.
for path_permutation in itertools.permutations(nodes):
current_path_cost = 0
current_path = [start_node] + list(path_permutation)
# 현재 순열의 경로 비용 계산합니다.
k = start_node
for next_node in path_permutation:
current_path_cost += graph[k][next_node]
k = next_node
# 마지막 노드에서 시작 노드로 돌아오는 비용을 추가합니다.
current_path_cost += graph[k][start_node]
# 최소 비용 경로를 업데이트합니다.
if current_path_cost < min_path_cost:
min_path_cost = current_path_cost
best_path = current_path + [start_node]
return best_path, min_path_cost
# 실행 및 결과를 확인합니다.
path, cost = tsp_brute_force(graph_simple, 'A')
print(f"완전 탐색 최적 경로: {path}")
print(f"완전 탐색 최단 거리: {cost}")
완전 탐색 최적 경로: ['A', 'B', 'D', 'E', 'C', 'A']
완전 탐색 최단 거리: 80
모든 경우의 수를 따져보니, A에서 시작하여 B, D, E, C를 순서대로 방문하고 다시 A로 돌아오는 경로가 총 80분으로 가장 짧다는 것을 확인했습니다. 간단한 문제에서는 확실한 답을 주지만, 건물이 10개만 되어도 경로의 수는 9!6) = 362,880개, 15개가 되면 14! = 약 870억 개로 폭발적으로 늘어나 사실상 사용이 불가능해집니다.
2. 동적 계획법(Dynamic Programming): 점화식처럼, 메모로 똑똑하게 풀기!
고등학교 수학 시간에 배운 점화식을 기억하시나요? 점화식을 처음 들어보는 학생도 괜찮습니다. 점화식은 간단히 말해 '이웃한 항들 사이의 관계를 나타낸 식'으로, "다음 값은 이전 값을 이용해 이렇게 구할 수 있다"는 규칙을 의미합니다. 예를 들어, 매일 저금통에 3개씩 동전을 넣는다면, n번째 날의 동전 개수 = (n-1)번째 날의 동전 개수 + 3 이라는 규칙을 식으로 나타낸 것이 바로 점화식이죠.
동적 계획법은 바로 이 점화식의 원리를 프로그래밍에 적용한 것입니다. 즉, 작은 문제의 답을 이용해 더 큰 문제를 해결하는 전략입니다.
동적 계획법은 크게 두 가지 핵심 아이디어를 바탕으로 합니다.
- 1. 문제를 작은 단위로 쪼개기: 해결하려는 큰 문제를 여러 작은 하위 문제(Subproblem)로 나눕니다.
- 2. 계산 결과 저장하고 재활용하기: 한 번 계산한 하위 문제의 답을 메모장(Memoization)에 저장해두고, 같은 문제가 다시 나오면 저장된 답을 가져와 중복 계산을 피합니다.
외판원 문제(TSP)에 이 방식을 적용해 봅시다. 예를 들어, '정문에서 출발하여 체육관과 경영대학을 거쳐 예술관에 도착하는 최단 경로'를 찾는다고 가정하겠습니다. 이 문제를 풀려면, '정문에서 출발하여 체육관을 거쳐 경영대학에 도착하는 최단 경로'와 같은 더 작은 문제들을 먼저 풀어야 합니다.
동적 계획법은 이때 '정문 → 체육관 → 경영대학'의 최단 시간을 계산한 뒤 그 결과를 '메모장'에 기록해 둡니다. 나중에 다른 경로를 탐색하다가 이와 동일한 하위 경로가 필요해지면, 처음부터 다시 계산하는 대신 메모장에 적어둔 값을 바로 가져와 사용하는 것입니다. 아래 코드 속의 memo = {} 부분이 바로 이 메모장 역할을 합니다. 동적 계획법은 바로 이 메모장에 이미 해결한 문제의 답을 버리지 않고 차곡차곡 쌓아 나갑니다. 이를 통해 완전 탐색의 막대한 중복 계산을 획기적으로 줄여 효율적으로 최적의 해를 찾아낼 수 있는 것입니다.
그런데 컴퓨터는 '어떤 건물들을 방문했는지' 상태를 어떻게 효율적으로 기록하고 확인할까요? 이때 비트마스킹(Bitmasking) 기법이 사용됩니다. 비트마스킹은 각 건물의 방문 여부를 0과 1, 즉 하나의 비트(bit)로 표현하고 하나의 숫자로 압축해 저장하는 방법입니다. 예를 들어, 방문할 건물이 총 5개이고 그중 1번과 3번 건물을 방문했다면, 이 상태를 이진수 10100으로 표현하는 식입니다. 컴퓨터는 이 숫자를 통해 어떤 건물을 방문했고 어떤 건물을 아직 방문하지 않았는지 빠르고 효율적으로 파악할 수 있습니다. 코드에서 방문 기록을 확인하는 부분이 바로 이 기법을 활용한 것입니다.
Python
# (현재 노드, 방문한 노드 집합)을 키(Key)로, 해당 상태까지 도달하는 '최단 거리'를 값(Value)으로 저장합니다.
memo = {}
# 'A', 'B', 'C'와 같은 건물 이름을 0, 1, 2와 같은 컴퓨터가 다루기 쉬운 숫자로 바꿉니다.
# 특히, 건물의 방문 여부를 0과 1로 표현하는 '비트마스크' 기법을 사용을 위해 필수적입니다.
nodes_map = {node: i for i, node in enumerate(nodes)}
# tsp_dp 함수: 동적 계획법으로 TSP 문제를 푸는 핵심 재귀 함수
# - graph: 전체 건물 간의 거리 정보가 담긴 그래프
# - current_node_idx: 현재 위치한 건물의 번호(인덱스)
# - visited_mask: 지금까지 어떤 건물들을 방문했는지 비트(0과 1)로 기록한 값
def tsp_dp(graph, current_node_idx, visited_mask):
# [재귀의 종료 조건]
# 모든 노드를 방문시 현재 위치->출발점 거리만 반환 후 종료합니다.
if visited_mask == (1 << len(nodes)) - 1:
start_node_name = nodes[0]
current_node_name = nodes[current_node_idx]
return graph[current_node_name][start_node_name]
# 메모이제이션: 계산 결과를 저장해두고 다음에 같은 계산을 다시 하는 대신 저장해둔 값을 가져다가 쓰는 기법
if (current_node_idx, visited_mask) in memo:
return memo[(current_node_idx, visited_mask)]
# 아직 계산된 적 없는 문제라면, 최소 비용을 무한대(가장 큰 값)로 초기화합니다.
min_cost = sys.maxsize
# 방문하지 않은 다음 노드로 이동합니다.
for next_node_idx in range(len(nodes)):
# 비트 연산(&)으로 next_node_idx에 해당하는 건물 이미 방문했는지 확인
if not (visited_mask & (1 << next_node_idx)):
# 다음 목적지까지의 경로 비용을 재귀적으로 계산합니다.
cost = graph[nodes[current_node_idx]][nodes[next_node_idx]] + \
tsp_dp(graph, next_node_idx, visited_mask | (1 << next_node_idx))
min_cost = min(min_cost, cost)
# [결과 기록 및 반환]
# 계산이 끝난 문제의 답(최소 비용)을 메모장에 기록합니다.
memo[(current_node_idx, visited_mask)] = min_cost
# 다음 재귀 호출을 위해 계산된 최소 비용을 반환합니다.
return min_cost
# 실행 및 결과 확인 (시작은 'A', 즉 인덱스 0에서)
cost_dp = tsp_dp(graph_simple, 0, 1)
print(f"동적 계획법 최단 거리: {cost_dp}")
동적 계획법 최단 거리: 80
동적 계획법도 완전 탐색과 동일한 최단 거리 80을 찾아냈습니다! 코드는 조금 복잡해 보이지만, 완전 탐색보다 훨씬 효율적으로 동작합니다. 하지만 이 방법 역시 건물의 개수가 20개를 넘어가면 메모리와 시간 문제에 부딪히게 됩니다.
3. Greedy MST 기반 근사 알고리즘: 완벽함을 포기하고 속도를 얻는다!
정확한 최적해를 찾는 것이 너무 오래 걸린다면, 약간의 오차를 감수하더라도 '충분히 좋은' 해를 빠르게 찾는 것이 더 현실적일 수 있습니다. 이것이 바로 근사 알고리즘의 매력입니다. 여기서는 그중 하나인 최소 신장 트리(MST) 기반의 그리디 알고리즘을 간단하게 소개합니다.
그리디(Greedy, 탐욕) 알고리즘은 말 그대로 "매 순간 그 상황에서 당장 가장 좋아 보이는 답을 선택하는" 방식으로 동작합니다. 그러나 지금의 선택이 미래에 어떤 영향을 미칠지는 전체적으로 고려하지 않기 때문에 지금 당장은 최선처럼 보여도, 최종 결과는 최적의 해가 아닐 수도 있습니다.
이 알고리즘은 다음의 간단한 세 단계로 동작합니다.
1단계: 최소 비용의 뼈대 만들기(MST 생성)
먼저, 모든 건물을 가장 효율적으로 잇는 최소 신장 트리(MST), 즉 '최소 비용의 뼈대'를 만듭니다. 이때도 그리디 방식이 사용되는데, 대표적으로 프림(Prim) 알고리즘의 아이디어를 따릅니다.
- 1) 임의의 건물 하나를 시작점으로 선택하여 '선택된 건물 그룹'에 추가합니다.
- 2) '선택된 건물 그룹'과 '선택되지 않은 건물 그룹' 사이를 연결한 도로 중 가장 짧은 도로를 선택합니다.
- 3) 해당 도로로 연결된 새로운 건물을 선택된 건물 그룹에 포함시킵니다.
- 4) 모든 건물이 선택된 건물 그룹에 포함될 때까지 2)와 3)의 과정을 반복합니다.
이렇게 '이미 연결된 집단에서 밖으로 뻗어 나가는 가장 짧은 길'을 계속해서 탐욕적으로 선택하며 전체 뼈대를 완성하는 것입니다.
2단계: : 뼈대를 따라 방문 순서 정하기
다음으로, 만들어진 뼈대(MST)를 따라 출발점부터 한붓그리기처럼 따라가며 방문 순서를 정합니다. 이것을 전위 순회(Pre-order Traversal)라고 합니다. 마치 미로를 탐험할 때 한쪽 벽을 계속 짚고 가는 것과 비슷합니다.
3단계: 최종 경로 완성
마지막으로, 이렇게 정해진 방문 순서대로 경로를 만들고, 맨 마지막 건물에서 다시 출발점으로 돌아오는 길을 이어주면 근사적인 최단 경로가 완성됩니다.
Python
# 1. graph_simple로부터 MST 생성(Prim 알고리즘 방식)
# - 'A'에서 시작. 연결된 가장 짧은 도로는 'A-B'(10). {A, B} 그룹 형성.
# - 현재 {A, B} 그룹. 다음 경로인 'D'와 연결된 'B-D'(25)를 추가. {A, B, D} 그룹 형성.
# - 현재 {A, B, D} 그룹. 다음 경로인 'E'와 연결된 'D-E'(10)를 추가. {A, B, D, E} 그룹 형성.
# - 현재 {A, B, D, E} 그룹. 마지막 남은 'C'와 연결된 'A-C'(15)를 추가. {A, B, C, D, E} 그룹 형성.
# - 모든 건물이 연결되어 MST 완성.
# 2. 생성된 MST를 'A'에서부터 전위 순회하여 방문 순서 결정
# -> 방문 순서: ['A', 'B', 'D', 'E', 'C']
# 3. 결정된 순서로 최종 경로를 만들고 비용 계산
# A→B(10) + B→D(25) + D→E(10) + E→C(20) + C→A(15) = 80
앗! 이번에는 최적해와 정확히 같은 80이라는 결과가 나왔네요. 모든 간선의 값이 양수인 특정 그래프에서는 탐욕적인 선택이 최적해와 일치할 수 있지만, 항상 최적해를 보장하는 것은 아닙니다. 그럼에도 계산 속도가 앞선 두 알고리즘에 비해 월등히 빠르다는 핵심적인 장점은 변치 않죠.
3단계. 외판원이 되어 서울대학교 캠퍼스를 누벼보아요!
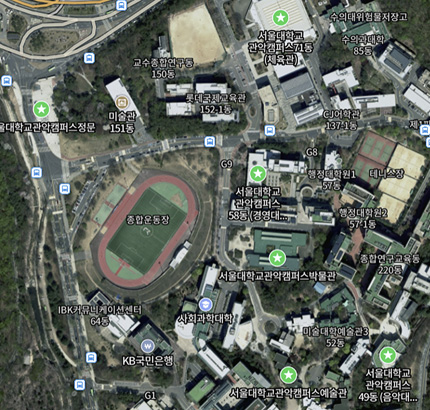
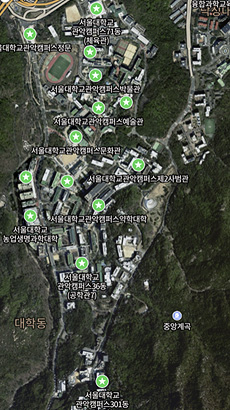
간단한 그래프에서는 세 알고리즘의 속도 차이를 체감하기 어렵습니다. 이제 실제 서울대학교의 주요 건물 14개로 구성된, 더 복잡한 그래프로 성능을 비교해 보겠습니다. 아래 사진은 서울대학교 주요 건물 14개를 선택한 네이버 지도 사진입니다.
| 완전 탐색 | 154 | 약 10~20분 |
| 동적 계획법 | 154 | 약 1.48초 |
| Greedy MST 근사 | 154 | 약 0.002초 |
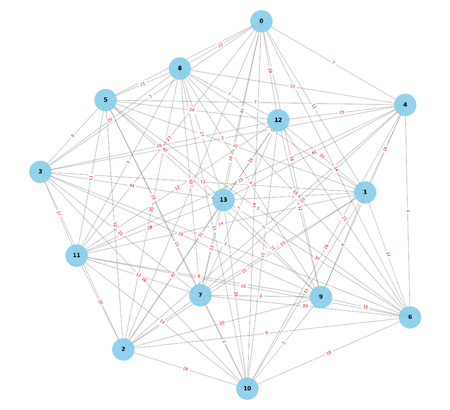
해당 건물을 노드로 하고 각 건물 사이의 도보 시간을 간선으로 하는 가중치 그래프를 그리면 아래와 같은 가중치 그래프가 그려집니다. 매우 복잡해보입니다. 91개(=14C2)개의 간선으로 이루어진 그래프이기 때문입니다. 노드에 매긴 값은 0번(서울대학교 정문) ~ 13번(서울대학교 301동)과 같이 고도가 낮을수록 낮은 값을 부여하였습니다. 이제 아래 그래프에 대해 앞서 소개한 3가지 알고리즘을 실행시킨 결과를 요약하면 다음과 같습니다.
완전 탐색으로 14개 건물을 모두 방문하는 경우의 수는 13! (팩토리얼)로, 약 62억 개에 달합니다. 컴퓨터가 1초에 약 천만(10,000,000) 개의 경로를 계산한다고 가정해 보더라도 623초 약 10분에 달하는 시간이 소요됩니다. 또한 만약 건물이 단 하나만 추가되어 15개가 되면 계산량은 14배로 늘어나 몇 시간이 걸릴 수 있기에, 복잡한 문제에서는 동적 계획법이나 근사 알고리즘과 같은 더 효율적인 접근 방식이 반드시 필요합니다.
반면 동적 계획법은 약 1.5초 만에 최적 경로의 총 이동 시간이 154분이라는 완벽한 답을 찾아냈습니다. 더 나아가 Greedy MST 근사 알고리즘은 매우 흥미로운 결과를 보여줍니다. 이번 사례에서는 최적해와 동일한 154분짜리 경로를 찾아냈지만, 실행 시간은 0.002초로 동적 계획법보다도 수백 배나 빨랐습니다.
근사 알고리즘이 찾은 경로는 최적 경로보다 더 긴 시간이 걸릴 수 있지만, 실행 시간은 수천 배나 빠릅니다. 만약 건물이 100개가 넘는 실제 물류 시스템이라면 어떨까요? 최적 경로를 찾기 위해 몇 분을 기다리는 것보다, 약간의 오차를 감수하고 몇 초 만에 효율적인 경로를 얻는 것이 훨씬 더 현명한 선택일 수 있습니다. 바로 이것이 정확성과 효율성 사이의 Trade-off7)에서 균형점을 찾는 공학적 사고의 핵심입니다.
결론: 효율적인 탐색, 공학적 사고의 힘!
이번 기사를 통해 우리는 서울대학교 캠퍼스를 예시로 삼아 외판원 문제와 다양한 경로 탐색 알고리즘을 살펴보았습니다. 완벽한 최적 해를 찾는 데 어려움이 있더라도, 더 빠르고 효율적인 근사적인 방법을 찾아내는 것 또한 공학적인 문제 해결 방식의 중요한 측면입니다. 이처럼 정확도와 속도의 Trade-Off 속에서 최고의 균형점을 찾는 고민은 비단 코딩에만 국한되지 않습니다. 제한된 시간과 자원 속에서 최선의 선택을 내려야 하는 것은 우리가 마주하는 많은 문제의 본질과도 같기 때문입니다. 여러분도 삶의 다양한 문제 속에서 자신만의 멋진 균형점을 찾아 나가길 응원하겠습니다.
참고
- 1) 공급망의 여러 환경(도로, 물류량)을 고려하여 최적의 창고 위치 등을 정하는 것
- 2) 전체 도시를 잇는 도로 중 몇 개의 도로만 선택해 모든 도시를 연결한 트리(신장 트리) 중 가장 짧은 트리
- 3) 간선(edge)에 할당된 숫자 값으로, 간선이 나타내는 연결의 비용, 거리, 시간 등 특정 값을 의미
- 4) 프로그래밍에서 키-값 쌍을 저장하는 자료형
- 5) 파이썬의 딕셔너리에서 원하는 데이터를 꺼내기 위해 사용하는 고유한 이름표
- 6) 1부터 특정 양의 정수 n까지의 모든 정수를 곱한 값. Ex) 5! = 1 × 2 × 3 × 4 × 5= 120
- 7) 두 개의 가치 있는 목표 중 하나를 얻으면 다른 하나를 잃게 되는 상충 관계